LLaMA C/C++
Website: https://github.com/ggerganov/llama.cpp (opens in a new tab)
The main goal of llama.cpp is to run the LLaMA model using 4-bit integer quantization on a MacBook (locally). This is currently supported only on Linux and MacOS.
Getting Started
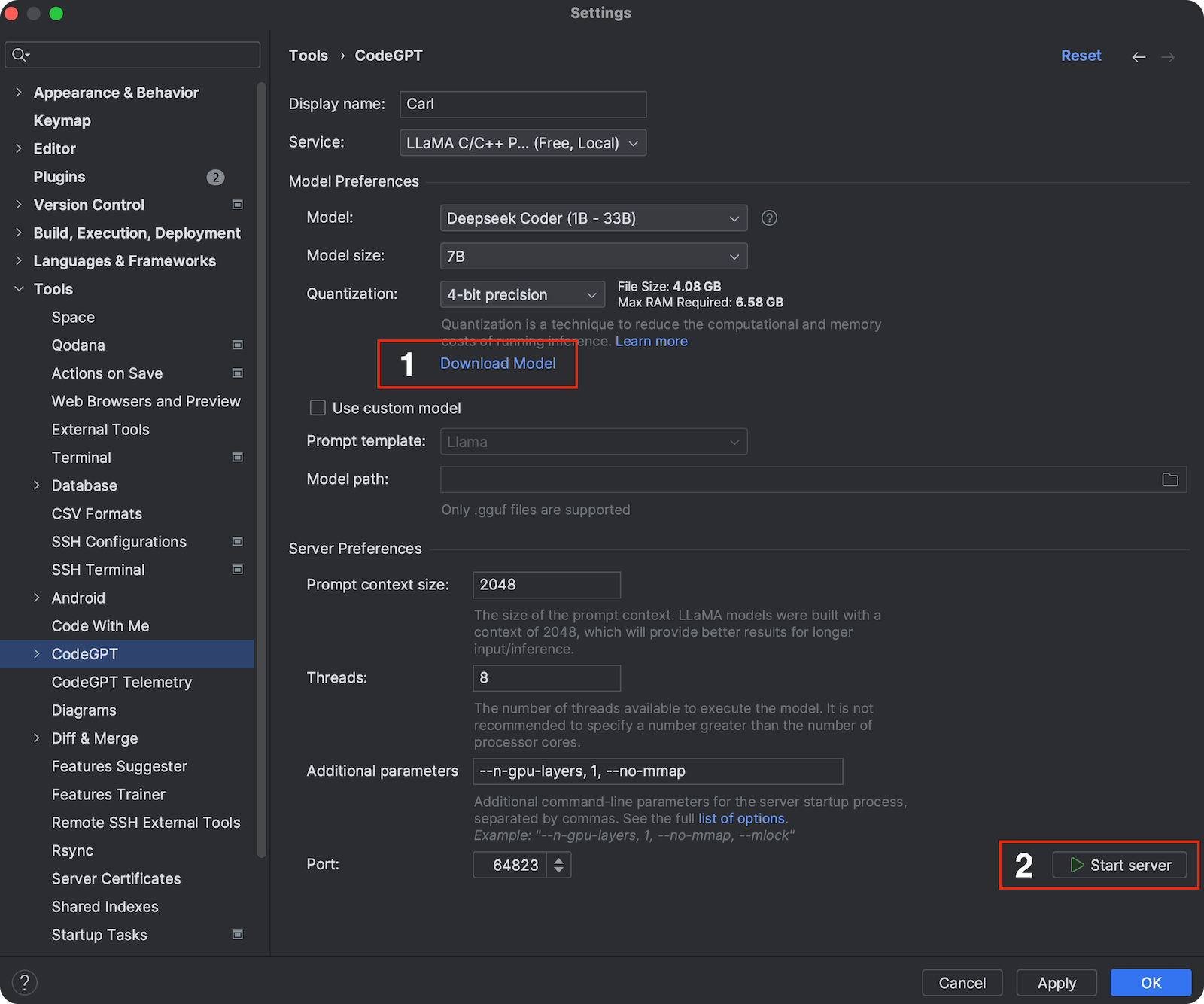
Select the Model
Choose the appropriate model based on your hardware capabilities from the provided list. Click Download Model to start the download. A progress bar will show the download progress.
Start the Server
Once the model is downloaded, click Start Server to initiate the server. A status message will indicate that the server is starting.
Apply Settings
With the server running, you can change settings, then click Apply or OK save your settings and start using the plugin.
Note: If you're already running a server and wish to configure the plugin against that, then simply select the port and click
ApplyorOK.